Juliette, un robot qui reconnaît les gestes par la vision

Et si les robots pouvaient interpréter nos gestes ? Mounim El Yacoubi est chercheur à Télécom SudParis, il étudie et réalise des systèmes de communication entre l’homme et la machine. A l’occasion de la Bourse aux technologies organisée à Evry par l’Institut Mines-Télécom sur le thème de l’e-santé, il présentera le 5 mars prochain le projet Juliette, un système de reconnaissance de geste par la vision. Implanté dans le robot Nao développé par la société Aldebaran Robotics, il permet de détecter 11 activités humaines et d’assister les personnes fragiles au quotidien.
« Juliette est un robot compagnon pour les personnes fragiles, destiné à vivre avec la personne dans un smart home. » Sa particularité : il est capable d’interpréter les gestes de son utilisateur. Il contient un système pour la reconnaissance du geste par la vision, développé par Mounim El Yacoubi et son équipe de chercheurs du groupe Intermedia de Télécom SudParis, capable d’analyser des séquences vidéo et de détecter une activité humaine en fonction des mouvements effectués.
Ce système a été développé dans le cadre du projet FEDER* Juliette, un projet de recherche partenariale monté avec la société Aldebaran Robotics, l’entreprise Brain Vision Systems (BVS) et l’Institut de la Vision.

Pour l’acquisition vidéo, les chercheurs ont utilisé seulement la caméra située sur la tête du robot.
« Nous avons développé des algorithmes qui permettent la perception visuelle du robot Nao, afin qu’il puisse monitorer des personnes fragiles, les assister et détecter les éventuels cas d’urgence, comme la chute, mais aussi tout comportement anormal, » explique Mounim El Yacoubi. Juliette reconnaît déjà 11 activités quotidiennes, parmi lesquelles marcher, ouvrir et fermer une porte, ou boire de l’eau. « Par exemple, si le robot ne détecte pas l’activité boire dans la journée, il peut en déduire que la personne n’a pas pris son médicament. » Et les chercheurs prévoient d’en développer beaucoup plus !
Un algorithme d’intelligence artificielle qui apprend automatiquement à distinguer de nouvelles activités
Pour apprendre au robot à reconnaître les activités humaines, il doit passer par une première phase d’apprentissage. « On demande à un certain nombre de personnes de répéter plusieurs fois les activités devant la caméra du robot pour obtenir des séquences vidéo, explique Mounim El Yacoubi. A partir de ce corpus d’apprentissage, un algorithme d’intelligence artificielle va calculer des paramètres qui vont lui permettre de différencier les activités. Puis, pendant la phase de test, on vérifie si le robot est capable de reconnaître les activités qu’on lui a apprises. » L’un des verrous pour reconnaître des activités humaines, c’est que les mouvements sont variables pour une même activité : les gens ne marchent pas de la même façon et une même personne ne marchera pas de la même façon d’une fois sur l’autre. « Qui dit variabilité dit incertitude et il faut donc faire appel à des modèles probabilistes. »
Pour que le système apprenne automatiquement comment distinguer les activités, « on a d’abord utilisé la technique du sac de mot (bag of words), qui permet de convertir une séquence en un vecteur statique. » Cette technique est beaucoup utilisée pour classer les documents textes sur le web en catégories. Le texte est considéré comme un sac de mots et l’algorithme calcule la fréquence de certains mots, répertoriés dans un dictionnaire de taille définie (par exemple, 1000 mots) : par exemple Barack Obama pour la catégorie politique ou football pour la catégorie sport. « On s’est inspiré de cette idée pour générer des “mots visuels” à partir de l’analyse du mouvement. »
La méthode consiste à poser une grille rectangulaire très dense sur la première image. « Cela génère un grand nombre de pixels aux intersections de la grille. » Leur évolution est suivie dans le temps pendant 15 images. S’il y a un mouvement, les pixels associés à une partie du corps vont se déplacer et générer une trajectoire, que le système pourra caractériser. En pratique, le nombre de trajectoires générées dépend du mouvement et est variable d’une activité à l’autre, ce qui va permettre de les différencier.
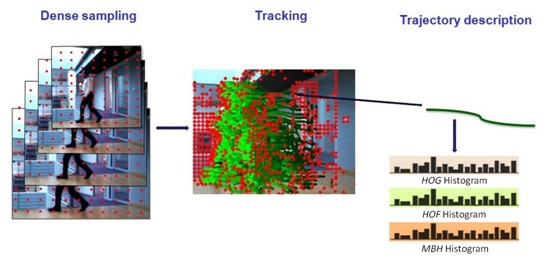
La technique du « sac de mots » en trois étapes : la mise en place de la grille, la détection des trajectoires (en vert) et leur caractérisation (les histogrammes de « mots visuels »).
L’étape suivante consiste donc à utiliser un algorithme de clustering (ici de type K-means) pour trouver des groupes de trajectoires similaires parmi toutes les vidéos du corpus d’apprentissage. « Le nombre de groupes est fixé à l’avance. Chaque groupe est représenté par son centre, un vecteur statique, que l’on appelle “mot visuel”. » A présent, chaque fois que le système devra traiter une vidéo, il affectera automatiquement chacune des trajectoires qu’il détecte à un des groupes prédéfinis. Le système peut désormais utiliser une méthode de classification statique, ici le modèle mathématique SVM (Support Vector Machine), pour classer les vidéos selon leur histogramme de “mots visuels”, qui correspond à une activité précise.
« Le plus complexe a été d’implémenter le système dans le robot. »
Ce système est particulièrement innovant car Mounim El Yacoubi et son équipe ont réussi à faire en sorte que Juliette soit complètement autonome et non pas liée à un ordinateur qui se chargerait du traitement de l‘image. « Le plus complexe a été d’implémenter le système dans le robot. » Nao a des ressources limitées : son microprocesseur est peu puissant contrairement à celui d’un ordinateur et sa mémoire n’est pas très importante. Cela crée des contraintes supplémentaires, qui ont conduit les chercheurs à optimiser tous les algorithmes pour que le système réponde dans des temps raisonnables. « Par exemple, pour l’acquisition du mouvement par la caméra, nous avons divisé par 4 la résolution d’image normale, et nous avons utilisé 12 images par seconde au lieu de 30. »
Pour les PME spécialisées en e-santé ou en accompagnement des personnes, Juliette présente plusieurs avantages en comparaison avec une simple caméra. D’abord, le robot est plus accepté par les personnes, car il n’est pas considéré comme un objet intrusif. Il peut aussi permettre de réduire les coûts en évitant les fausses alertes. « Par exemple, en cas de chute, il pourra aller vers la personne et entamer une communication afin de vérifier si tout va bien. Il ne déclarera le cas d’urgence qu’en cas de réelle absence de réponse. » Et les robots compagnons ne sont qu’au début de leur développement.
Résoudre les difficultés d’apprentissage des enfants fragiles
Mounim El Yacoubi et son équipe vont développer le nombre d’activités reconnues et améliorer le temps de traitement de Juliette. Le projet Cassiopée, qui mobilise des étudiants de deuxième année de Télécom SudParis et qui a commencé en février 2015, va faire en sorte que Juliette puisse continuer à apprendre dans le temps. Les chercheurs veulent aussi et surtout développer l’assistance aux personnes fragiles, et en particulier aux enfants présentant des troubles envahissants du développement de type autistique. « On sait que les personnes autistes ont besoin de stimulation cognitive et je pense que ce genre de système pourrait servir à développer des jeux sérieux engageant une interaction entre l’enfant et le robot. Il y a un certain nombre d’applications que j’aimerais développer, par exemple pour que l’enfant s’entraine à fixer du regard ou à pointer un objet du doigt, » précise Mounim El Yacoubi. Selon lui, résoudre les difficultés d’apprentissage des enfants fragiles sera à l’avenir un des enjeux majeurs de l’e-santé.
*Fonds Européen de Développement Régional
En savoir + sur la Bourse aux Technos de l’Institut Mines-Télécom
En savoir + sur le projet Juliette
En savoir + sur le robot Nao
En savoir + sur les travaux du groupe Intermédia de Télécom SudParis








Trackbacks (rétroliens) & Pingbacks
[…] aider les patients à vivre quotidiennement avec la maladie d’Alzheimer : il s’agit de Juliette, un système de reconnaissance de geste par la vision, implanté dans le robot Nao développé par la société Aldebaran Robotics. Capable […]
Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !